Environments
Index
This page describes in details all general aspects related to DIAMBRA Arena environments. For game-specific details visit Games & Specifics page.
Overview
DIAMBRA Arena is a software package featuring a collection of high-quality environments for Reinforcement Learning research and experimentation. It provides a standard interface to popular arcade emulated video games, offering a Python API fully compliant with OpenAI Gym/Gymnasium format, that makes its adoption smooth and straightforward.
It supports all major Operating Systems (Linux, Windows and MacOS) and can be easily installed via Python PIP, as described in the installation section. It is completely free to use, the user only needs to register on the official website.
In addition, its GitHub repository provides a collection of examples covering main use cases of interest that can be run in just a few steps.
Main Features
All environments are episodic Reinforcement Learning tasks, with discrete actions (gamepad buttons) and observations composed by screen pixels plus additional numerical data (RAM states like characters health bars or characters stage side).
They all support both single player (1P) as well as two players (2P) mode, making them the perfect resource to explore all the following Reinforcement Learning subfields:






Available Games
Interfaced games have been selected among the most popular fighting retro-games. While sharing the same fundamental mechanics, they provide different challenges, with specific features such as different type and number of characters, how to perform combos, health bars recharging, etc.
Whenever possible, games are released with all hidden/bonus characters unlocked.
Additional details can be found in their dedicated section.









Interaction Basics
DIAMBRA Arena Environments usage follows the standard RL interaction framework: the agent sends an action to the environment, which process it and performs a transition accordingly, from the starting state to the new state, returning the observation and the reward to the agent to close the interaction loop. The figure below shows this typical interaction scheme and data flow.
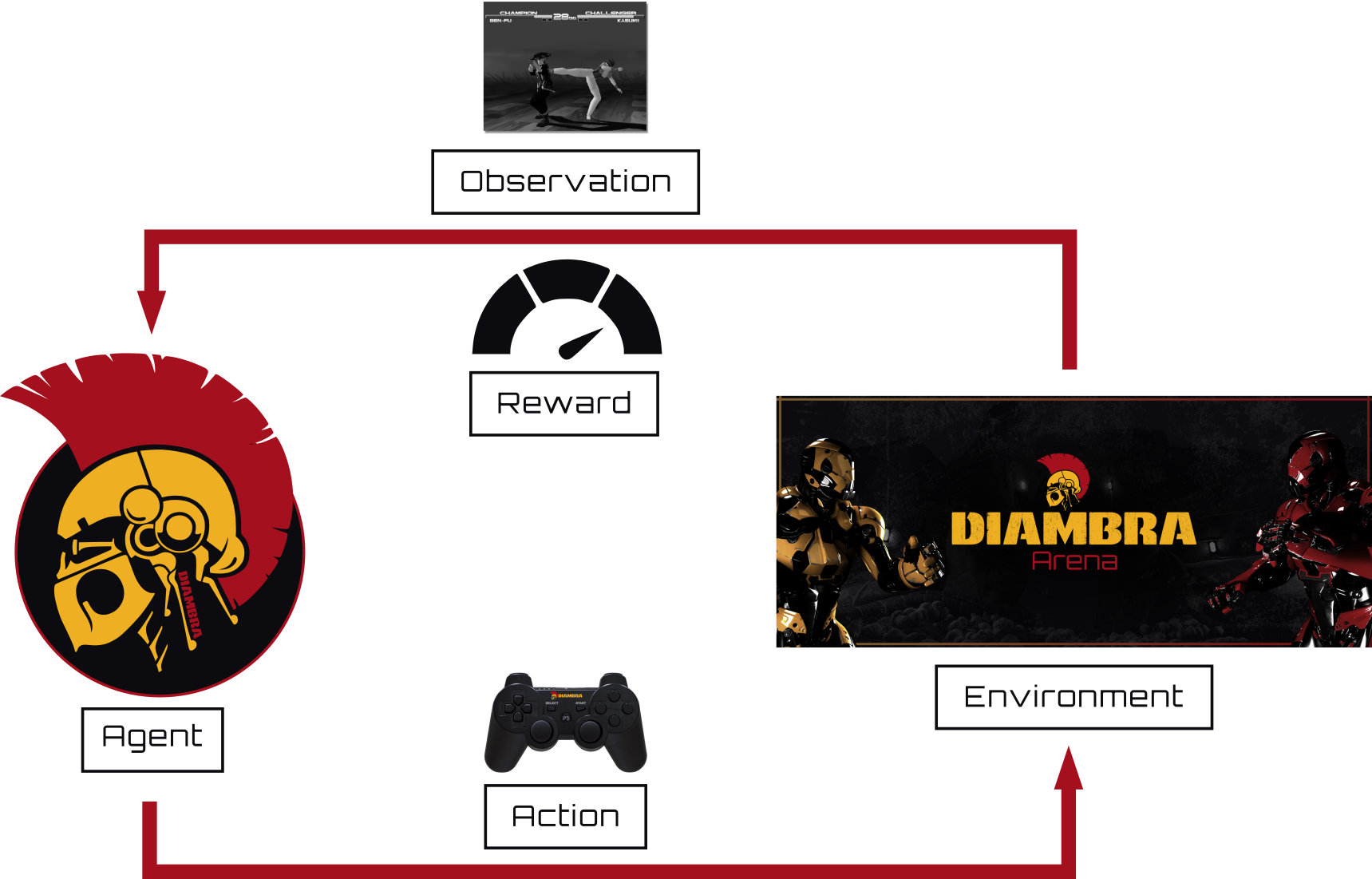
The shortest snippet for a complete basic execution of an environment consists of just a few lines of code, and is presented in the code block below:
#!/usr/bin/env python3
import diambra.arena
def main():
# Environment creation
env = diambra.arena.make("doapp", render_mode="human")
# Environment reset
observation, info = env.reset(seed=42)
# Agent-Environment interaction loop
while True:
# (Optional) Environment rendering
env.render()
# Action random sampling
actions = env.action_space.sample()
# Environment stepping
observation, reward, terminated, truncated, info = env.step(actions)
# Episode end (Done condition) check
if terminated or truncated:
observation, info = env.reset()
break
# Environment shutdown
env.close()
# Return success
return 0
if __name__ == '__main__':
main()More complex and complete examples can be found in the Examples section.
Settings
All environments have different options that can be specified using a dedicated EnvironmentSettings class. They are nested as follows:
- Environment settings: defined only when the environment is instantiated, they never change throughout the agent-environment interaction (e.g. the action space or the frame size)
- Episode settings: defined first when the environment is instantiated, they can be changed each time a new episode starts, i.e. at every environment
resetcall, passing a dictionary containing the key-value pairs for the settings of interest through theoptionskeyword argument. These settings are further divided in:- Game settings: they specify features of the game (e.g. difficulty level)
- Player settings: they specify player-related aspects (e.g. selected character and its outfits)
- Episode settings: defined first when the environment is instantiated, they can be changed each time a new episode starts, i.e. at every environment
Settings specifications when instantiating the environment is done by passing the EnvironmentSettings class, properly filled, to the environment make call as follows:
from diambra.arena import EnvironmentSettings
# Settings specification
settings = EnvironmentSettings()
settings.setting_1 = value_1
settings.setting_2 = value_2
env = diambra.arena.make("doapp", settings)
The first argument is the game_id string, it specifies the game to execute among those available (see games list for details).
Episode settings specification at reset is done by passing the episode_settings dictionary to the environment reset call as follows:
# Episode settings
episode_settings = {
setting_1: value_1,
setting_2: value_2,
}
env.reset(options=episode_settings)
Some of them are shared among all environments and are presented here below, while others are specific to the selected game and can be found in the game-specific pages listed here.
The tables in the next sections lists all the attributes of the setting classes.
Use dictionaries to specify settings
As for previous versions of the library, it is also possible to specify environment settings through a dictionary and use a dedicated function to load it into the EnvironmentSettings class:
from diambra.arena import EnvironmentSettings, load_settings_flat_dict
# Settings specification
settings = {
setting_1: value_1,
setting_2: value_2,
}
settings = load_settings_flat_dict(EnvironmentSettings, settings)
env = diambra.arena.make("doapp", settings)
When using multi-agents (two players) environments, the settings class to be passed to the environment make method is the EnvironmentSettingsMultiAgent instead of EnvironmentSettings, while all the attributes will remain the same.
Following OpenAI Gym/Gymnasium standard, also the seed can be specified at reset using env.reset(seed=seed, options=episode_settings), but please note that:
• It can be directly passed through the settings dictionary when the environment is instantiated and the environment will take care of setting it at the first reset call
• When explicitly passed to the reset keyword argument, it should only be passed to the very first reset method call and never after it
Environment Settings
| Name | Type | Default Value(s) | Value Range | Description |
|---|---|---|---|---|
frame_shape | tuple of three int (H, W, C) | (0, 0, 0) | H, W: [0, 512] C: 0 or 1 | If active, resizes the frame and/or converts it from RGB to grayscale. Combinations: (0, 0, 0) - Deactivated; (H, W, 0) - RGB frame resized to H X W; (0, 0, 1) - Grayscale frame; (H, W, 1) - Grayscale frame resized to H X W. |
action_space* | SpaceTypes | MULTI_DISCRETE | DISCRETE / MULTI_DISCRETE | Defines the type of the action space |
n_players | int | 1 | [1, 2] | Selects single player or two players mode |
step_ratio | int | 6 | [1, 6] | Defines how many steps the game (emulator) performs for every environment step |
splash_screen | bool | True | True / False | Activates displaying the splash screen when launching the environment |
*: must be provided as tuples of two elements (for agent_0 and agent_1 respectively) when using the environments in two players mode.
Episode Settings
Game Settings
| Name | Type | Default Value(s) | Value Range | Description |
|---|---|---|---|---|
difficulty | None U int | None | Game-specific min and max values allowed | Specifies game difficulty (1P only) |
continue_game | float | 0.0 | [0.0, 1.0]: probability of continuing game at game overint(abs(-inf, -1.0]): number of continues at game over before episode to be considered done | Defines if and how to allow ”Continue” when the agent is about to face the game over condition |
show_final | bool | False | True / False | Activates displaying of final animation when game is completed |
Other variable game settings are found in the game-specific pages where applicable.
Player Settings
Environment settings depending on the specific game and shared among all of them are reported in the table below. Additional ones (if present) are reported in game-dedicated pages.
| Name | Type | Default Value(s) | Value Range | Description |
|---|---|---|---|---|
role* | None U Roles | None | P1 (left), P2 (right), None (50% P1, 50% P2) | Selects role for the player, which also affects the side positioning at round starts |
characters* | None U str U tuple of maximum three str | None | Game-specific lists of characters that can be selected | Specifies character(s) to use |
outfits* | int | 1 | Game-specific min and max values allowed | Defines the number of outfits to draw from at character selection |

Other variable player settings are found in the game-specific pages where applicable.
*: must be provided as tuples of two elements (for agent_0 and agent_1 respectively) when using the environments in two players mode.
None values specify a Random behavior for the correspondent parameter.
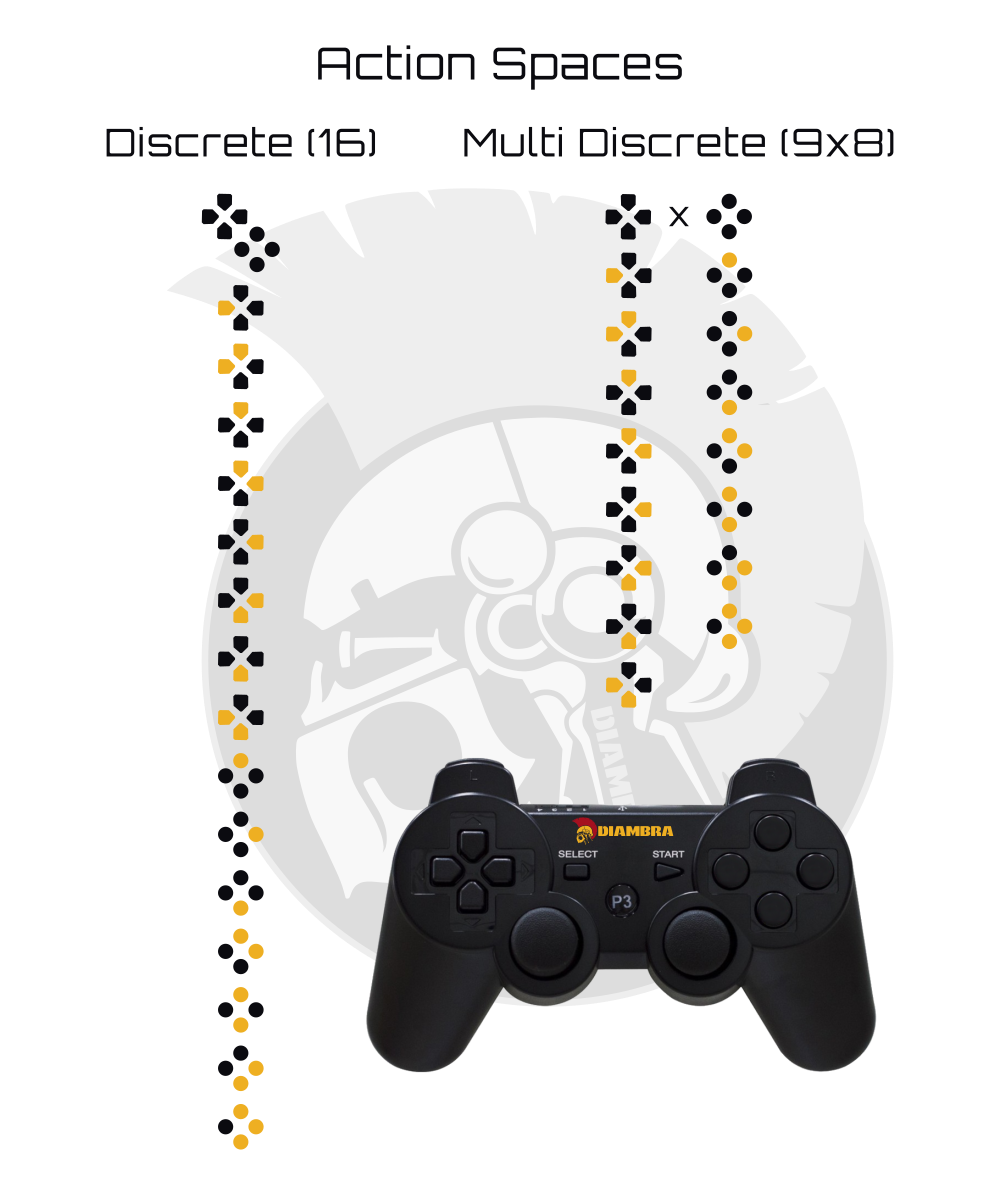
Action Space(s)
Actions of the interfaced games can be grouped in two categories: move actions (Up, Left, etc.) and attack ones (Punch, Kick, etc.). DIAMBRA Arena provides two different action spaces: Discrete and MultiDiscrete. The former is a single list composed by the union of move and attack actions (of type gymnasium.spaces.Discrete), while the latter consists of two sets combined, for move and attack actions respectively (of type gymnasium.spaces.MultiDiscrete). The complete visual description of available action spaces is shown in the figure below, where both choices are presented via the correspondent gamepad buttons configuration for Dead Or Alive ++.
When run in 2P mode, the environment is provided with a Dictionary action space (type gymnasium.spaces.Dict) populated with two items, identified by keys agent_0 and agent_1, whose values are either gymnasium.spaces.Discrete or gymnasium.spaces.MultiDiscrete as described above.
Each game has specific action spaces since attack buttons (and their combinations) are, in general, game-dependent. For this reason, in each game-dedicated page, a table like the one found below is reported, describing both actions spaces for the specific game.
In Discrete action spaces:
- There is only one ”no-op” action, that covers both the ”no-move” and ”no-attack” actions.
- The total number of actions available is Nm + Na − 1 where Nm is the number of move actions (no-move included) and Na is the number of attack actions (no-attack included).
- Only one action, either move or attack, can be sent for each environment step.
In MultiDiscrete action spaces:
- There is only one ”no-op” action, that covers both the ”no-move” and ”no-attack” actions.
- The total number of actions available is Nm × Na.
- Both move and attack actions can be sent at the same time for each environment step.
All and only meaningful actions are made available per each game: they are sufficient to cover the entire spectrum of moves and combos for all the available characters. If a specific game has Button-1 and Button-2 among its available actions, and not Button-1 + Button-2, it means that the latter has no effect in any circumstance, considering all characters in all conditions.
Some actions (especially attack buttons combinations) may have no effect for some of the characters: in some games combos requiring attack buttons combinations are valid only for a subset of characters.
For every game, a table containing the following info is reported. It provides numerical details about action spaces sizes.
| Type | Space Size (Number of Actions) |
|---|---|
| Discrete / MultiDiscrete | Total number of actions available, divided in move and attack actions |
Observation Space
Environment observations are composed by two main elements: a visual one (the game frame) and an aggregation of quantitative values called RAM states (stage number, health values, etc.). Both of them are exposed through an observation space of type gym.spaces.Dict. It consists of global elements and player-specific ones, they are presented and described in the tables below. To give additional context, next figure shows an example of Dead Or Alive ++ observation where some of the RAM States are highlighted, superimposed on the game frame.
Each game specifies and extends the set presented here with its custom one, described in the game-dedicated page.

Global
Global elements of the observation space are unrelated to the player and they are currently limited to those presented and described in the following table. The same table is found on each game-dedicated page reporting its specs:
| Key | Type | Value Range | Description |
|---|---|---|---|
frame | Box | Game-specific min and max values for each dimension | Latest game frame (RGB pixel screen) |
stage | Box | Game-specific min and max values | Current stage of the game |
timer | Box | [0, round duration] | Round time remaining |
Player specific
Player-specific observations are nested under the key indicating the player they are referred to (i.e. "P1" and "P2"). A code example is shown below for the side RAM state of the two players:
# P1 side
P1_side = observation["P1"]["side"]
# P2 side
P2_side = observation["P2"]["side"]
Typical values that are available for each game are reported and described in the table below. The same table is found in every game-dedicated page, specifying and extending (if needed) the observation elements set.
| Key | Type | Value Range | Description |
|---|---|---|---|
side | Discrete (Binary) | [0, 1] | Side of the stage where the player is 0: Left, 1: Right |
wins | Box | [0, max number of rounds] | Number of rounds won by the player for the current stage |
character | Discrete | [0, max number of characters - 1] | Index of character in use |
health | Box | [0, max health value] | Health bar value |
Additional observations, both new and derived from specific processing of the above ones, can be obtained via the wide choice of Environment Wrappers, see the dedicated page for details.
Reward Function
The default reward is defined as a function of characters health values so that, qualitatively, damage suffered by the agent corresponds to a negative reward, and damage inflicted to the opponent corresponds to a positive reward. The quantitative, general and formal reward function definition is as follows:
$$ \begin{equation} R_t = \sum_i^{0,N_c}\left(\bar{H_i}^{t^-} - \bar{H_i}^{t} - \left(\hat{H_i}^{t^-} - \hat{H_i}^{t}\right)\right) \end{equation} $$
Where:
- $\bar{H}$ and $\hat{H}$ are health values for opponent’s character(s) and agent’s one(s) respectively;
- $t^-$ and $t$ are used to indicate conditions at ”state-time” and at ”new state-time” (i.e. before and after environment step);
- $N_c$ is the number of characters taking part in a round. Usually is $N_c = 1$ but there are some games where multiple characters are used, with the additional possible option of alternating them during gameplay, like Tekken Tag Tournament where 2 characters have to be selected and two opponents are faced every round (thus $N_c = 2$);
The lower and upper bounds for the episode total cumulative reward are defined in the equations (Eqs. 2) below. They consider the default reward function for game execution with Continue Game option set equal to 0.0 (Continue not allowed).
$$ \begin{equation} \begin{gathered} \min{\sum_t^{0,T_s}R_t} = - N_c \left( \left(N_s-1\right) \left(N_r-1\right) + N_r\right) \Delta H \\ \max{\sum_t^{0,T_s}R_t} = N_c N_s N_r \Delta H \end{gathered} \end{equation} $$
Where:
- $N_r$ is the number of rounds to win (or lose) in order to win (or lose) a stage;
- $T_s$ is the terminal state, reached when either $N_r$ rounds are lost (for both 1P and 2P mode) or game is cleared (for 1P mode only);
- $t$ represents the environment step and for an episode goes from 0 to $T_s$;
- $N_s$ is the maximum number of stages the agent can play before the game reaches $T_s$.
- $\Delta H = H_{max} - H_{min}$ is the difference between the maximum and the mimnimum health values for the given game; ususally, but not always, $H_{min} = 0$.
For 1P mode $N_s$ is game-dependent, while for 2P mode $N_s=1$, meaning the episode always ends after a single stage (so after $N_r$ rounds have been won / lost be the same player, either agent_0 or agent_1).
For 2P mode, agent_0 reward is defined as $R$ in the reward Eq. 1 and agent_1 reward is equal to $-R$ (zero-sum games). Eq. 1 describes the default reward function. It is of course possible to tweak it at will by means of custom Reward Wrappers.
The minimum and maximum total cumulative reward for the round can be different than $N_c\Delta H$ in some cases. This may happen because:
- When multiple characters are used at the same time, the
round_donecondition can be different for different games (e.g. either at least one character has zero health or all characters have zero health) impacting on the amount of reward collected. - For some games, health bars can be recharged (e.g. the character in background in Tekken Tag Tournament, or Gill’s resurrection move in Street Fighter III), making available an extra amount of reward to be collected or lost in that round.
- For some games, in some stages, additional opponents may be faced (opponent $N_c$ not constant through stages), making available an extra amount of reward to be collected (e.g. the endurance stages in Ultimate Mortal Kombat 3).
- For some games, not all characters share the same maximum health. $H_{max}$ and $H_{min}$ are always the extremes for a given game, among all characters.
Lower and upper bounds of episode total cumulative reward may, in some cases, deviate from what defined by Eqs. 2, because:
- The absolute value of minimum / maximum total cumulative reward for the round can be different from $N_c\Delta H$ (see above).
- For some games, $N_r$ is not the same for all the stages (1P mode only), for example for Tekken Tag Tournament the final stage is made of a single round while all previous ones require two wins.
Please note that the maximum cumulative reward (for 1P mode) is obtained when clearing the game winning all rounds with a perfect ($\max{\sum_t^{0,T_s}R_t}\Rightarrow$ game completed), but the vice versa is not true. In fact, not necessarily the higher number of stages won, the higher is the total cumulative reward ($\max{\sum_t^{0,T_s}R_t}\not\propto$ stage reached, game completed $\nRightarrow\max{\sum_t^{0,T_s}R_t}$). Somehow counter intuitively, in order to obtain the lowest possible total cumulative reward the agent is supposed to reach the final stage (collecting negative rewards in all previous ones) before loosing by $N_r$ perfects.
Normalized Reward
If a normalized reward is considered, the total cumulative reward equation becomes:
$$ \begin{equation} R_t = \frac{\sum_i^{0,N_c}\left(\bar{H_i}^{t^-} - \bar{H_i}^{t} - \left(\hat{H_i}^{t^-} - \hat{H_i}^{t}\right)\right)}{N_k \Delta H} \end{equation} $$
With the following additional term at the denominator:
- $N_k$ is the reward normalization factor defined through our reward nomralization wrapper.
The normalization term at the denominator ensures that a round won with a perfect (i.e. without losing any health), generates always the same maximum total cumulative reward (for the round) accross all games, equal to $N_c/N_k$.